
.NET can be treated as consisting of three parts - the Framework Class Library, .NET Languages, and .NET Runtime. This chapter addresses the features of the .NET runtime
The .NET Runtime executes code written in .NET languages and compiled to Intermediate Language- IL. This means that there are several issues that the .NET runtime must address - issues like .NET languages, security, memory management, interop with COM and so on. This section focuses on these issues
.NET Language compiler extend from those that merely compile scripting code (.NET consumers) to those that allow you to write your own type and extend existing types (.NET extenders). .NET language compilers compile code into IL that is Just0In-Time compiled at runtime and executed by the .NET executable engine.
At the heart of .NET languages is the Common Type System (CTS) which defines reference and value types as a standard that all .NET languages must follow when compiling code. The base set of features that a language compiler must follow to allow type to be used and extended by other languages is defined in the Common Language Specification (CLS). If a tool obeys this set of rules and therefore CLS-compliant, the types it generates can be used by code generated from another CLS-compliant code. It is for this reason that the .NET Runtime is called the Common Language Runtime (CLR). However, not that the CLR can execute the opcode of one only language -IL. the term CLR comes from the fact that the IL can be generated from more than one language.
To a certain extent the IL generated by the various .NET compilers is more or less the same. However, note that because the C++ complier performs some optimizations on the IL that it produces, the code generated from the managed C++ complier will perform better than that produced by the C# or VB.NET compilers. Also note that some languages provide conveniences to the programmer that results in extra IL. For example, late binding in VB.NET results in extra IL that is called at runtime to locate and load the requested methods.
IL is just one part of the data used by .NET. Another part of the data is called metadata. Metadata describes types in .NET. This is extremely important because it allows the runtime to check if the code that is being loaded is the same type as the code that the calling code expects to call. This protects uses from security violations and protects memory from corruption.
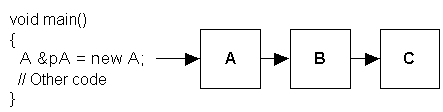
The following figure shows how code is executed in .NET:
Note the following important items that summarizes how .NET executes code:
(Note: This section is covered in more detail in Interoperation and COM+ chapter.)
.NET code has four ways for interoperating with non-.NET code:
One of the problems with Win32 native libraries was that different languages used different memory allocators. .NET provides a single source of allocated memory - the .NET managed heap. The .NET managed heap is managed by the garbage collector.
// C++ Example. Use the __pin
keyword to pin pointers in memory
__gc struct A { int i; };
// Managed function
#pragma managed
void main()
{
// Create an instance of some class
A *pA = new A;
// Retrieve and pin a pointer to a
member. Because pN will be passed to an unmanaged function, the GC will not
// able to track its usage or change its value when the
managed pA is moved around in memory. Therefore, to
// avoid corrupting pN (when pA is moved during garbage collection),
we pin pN to a fixed memory. This ensures
// that pA will not be moved around in memory
int __pin* pN = &(pa->i);
// Now use the pinned pointer in
unmanaged code
foo( pN );
// Once pN goes out of scope or is
assigned to zero, the object is unpinned and can be moved by the
// GC the next time it does garbage collection
}
// Unmanaged function.
#pragma unmanaged // this pragma
ensures code is compiled as native code
void foo( int *pNum)
{
std::cout << "pointer is at " << pNum;
}
// C# Example. C# has two
mechanisms for pinning. First, unsafe keyword is
used to flag code that is allowed to use direct pointers. Second, it allows you
to obtains pointer and pin objects in fixed
blocks
using System;
class A {public int i; }
class App
{
static void Main()
{
// Create a new
instance of A, initialize its data member, then pass it to foo()
A a = new A;
a.i = 0;
foo
(a)
}
// Because foo uses the unsafe keyword,
the code must be compiled with the /unsafe compiler switch
static unsafe void foo(A a)
{
// Create a
fixed pointer. This pins the a object in memory during the scope of foo
fixed (int* pI = &a.i)
// Use pI ...
}
}
// Memory clean up
public class Car : IDisposable
{
// Having a destructor means the object
is finalizable. When garbage collection occurs, release resources here
// This is another way to release resources if the user
forgot to call Dispose() - but we do not know when
// it will happen, only if GC.Collect() is called
~Car()
{
Dispose();
}
// Our custom Dispose method is
explicitly called by object users to free resources held by this instance
public void Dispose()
{
// Free
resources here
...
// No need to
finalize this object if user called Dispose(), so suppress finalization
GC.SuppressFinalize( this );
}
}
public class CApp
{
static void Main()
{
// Create 4
instances of Car
Car C1 = new Car;
Car C2 = new Car;
Car C3 = new Car;
Car C4 = new Car;
// Manually
dispose C1 and C2. This well the GC to suppress finalization for C1 and C2
C1.Dispose();
C2.Dispose();
// Call
Finalize() for all other objects on the finalization queue
GC.Collect();
}
}
/* C# using scopes an object so that
its Dispose() implementation is called when the object goes out of scope. Note
that using does not destroy the object */
using (TextWriter tw = File.AppendText("MyFile.txt")
{
string result = GetStringFromSomewhere();
tw.Write( result );
} // tw goes out of scope here.
Dispose() is then called. Dispose() should do all required cleanup
// Do not call any methods of tw here since it is now out
of scope
...

// C#
public class C
{
private WeakReference b = null;
// An instance of C holds on to a weak
reference of B by creating an instance of System.WeakReference class
// based on the passed B object. The GC will not tread the
member C.b as a reference to a B object because it
// is a weak reference. The whole point of creating this
reference is to allow the C object to access the
// B object, so we create a strong reference to B in the
function UseB
public C(B bref)
{
b = new WeakReference(bref);
}
public void UseB()
{
// Get a local
strong reference from a weak reference. Because the strong reference is local,
it is
// scoped. This means we can access
the object in this method
B bref = (B)b.Target;
// Use bref ...
}
}
Win32 is based on threads obtaining an access token and then performing an action on a secured object. The function that performs the action does an access check on the access token against an access control list (ACL) that has been created for the object.
.NET security sits on top of Win32 security, so you always get Win32 access checking and authentication. In addition, you get Code Access Security (CAS). CAS enforces security based on the identity of the code and not that of the user. .NET checks the source of the code (where it originates) and uses that information to determine whether to grant that code access to your HD.
The criteria that .NET uses to determine permissions are called evidence: the directory where the code resides, the URL from which the code was downloaded, the security zone, the strong name of the assembly, and the publisher of the assembly. From evidence, .NET uses a security policy to create a permission set, a group of permissions to perform certain actions. The basic idea is that the permissions given determine how trusted the code is.
However, the evidence does not involve just your code. .NET security gathers evidence from all code in the stack. So if your code tries to access the HD, the security system will check against the security policies set for the machine to see if your code is allowed to do this. If it is, then the security system will then check the code that called your code, determining its evidence and checking for the corresponding permissions. If calling code in the stack comes from an untrusted source, the permissions granted to your code will be reduced accordingly. This process is repeated for all code in the stack.
The permissions granted are based on the security policy. This policy is determined on three levels: machine settings, user settings, and domain settings ( a domain is a unit of isolation within a process that hosts the .NET runtime). The user and machine settings are stored in administrative files and are configured with Framework SDK tools. The domain settings are specified at runtime in the code.
The permissions granted to your code do not automatically pass to the calling code, and thus the calling code is not allowed to do any more that it is trusted to do. However, because permissions are determined on the basis of evidence gathered from all code in the call stack, your code may not have the permissions to do what it needs to do. Therefore, .NET gives your code the ability to specify that it needs a certain permission, regardless of the trust level of the code that called your code. This in effect says that the stack trace check should not be performed further up the stack.
C# classes are reference types. However, managed C++ uses the __gc and __value modifiers to determine if a type is a reference or value types.
/* To delcare a managed class in C++
use the __gc modifier. A C++ class declared without the __gc modifier means that
instances
of that class are unmanaged. Objects of an unmanaged class are created in the
unmanaged heap */
__gc class CPerson
{
...
};
// C# - All garbage collected
classes must be created with the new operator
CPerson developer = new CPerson(); // Parenthesis
must be used when calling the default parameterless constructor
developer.LearnDOTNET();
// Note the use of the dot operator
// C++ - All garbage
collected classes must be created with the new operator
CPerson developer = new CPerson;
developer->LearnDOTNET();
// The following is bad code. All __gc classes must be
created using the new operator. You cannot create
// __gc classes on the stack
CPerson dba
// C++
// The pA pointer is created outside the method in which
it is used
A *pA = new A;
UseA( pA );
void UseA( A* pA )
{
AC->SomeFunction();
}
// The pB pointer is created inside a method. Note that it
returns a pointer to a pointer
B *pB = 0;
CreateB( &pB );
void CreateB( B ** ppB )
{
*pB = new B;
}
// C#
// C# objects are passed by value (as in C++)
B b = 0;
CreateB( ref b);
// This is the equivalent of CreateB in C++
void CreateB(ref B b ) //
It makes better sense to use out instead of ref parameter
{
b = new B;
}
In .NET the terms managed and unmanaged always refer to how the storage for the instances of the type are maintained. A managed type is always created using the new operator and is therefore allocated from the managed heap. In C++, an unmanaged type can be created on the stack, but if it is created on the heap, the unmanaged version of new will be used and thus it will be created on the unmanaged heap. This means that the unmanaged delete operator must be used to clean up memory.
Boxing is a .NET mechanism for converting from a value type to a reference type. Unboxing does the opposite; it coverts from a reference type to a value type.
Boxing comes from the fact that the runtime creates a new instance of the value type wrapped (boxed) by a runtime-created wrapper. In C#, boxing happens automatically. However, because boxing involves creating a new object on the managed heap, C++ requires that you use the __box keyword to that it is clear that a new object is being created. A boxed object is always created on the managed heap. Note that the boxed object (in C# and C++) is a wrapper of the value type - and hence it has all the members of the value type:
// C#
public struct point
{
int x;
int y;
}
// Create and initialize an instance of point
point pt;
pt.x = 0;
pt.y = 0;
// Convert (box) from type point to an object. Note that
'ob' is a new object created on the heap (new was
// not used). More importantly note that changing the value of 'ob' does not
change the value of 'pt'
object ob = a;
// Unbox the value back. You need to tell the runtime what
value type you want
point b = (point)ob;
// C++
point pt;
pt.x = pt.y = 0;
Object *pOb = __box(a);
If you create an array of value types, sufficient space is allocated on the heap for all the elements, and the values are copied into this buffer:
// C#
int[] nNumbers = new int[2];
nNumbers[0] = 1;
nNumbers[1] = 2;
When you allocate an array of reference types, space is reserved for pointers to that type, so you have to allocate those objects yourself:
// C#
URL[] urls = new URL[2];
urls[0] = new URL("www.diranieh.com");
urls[1] = new URL("www.dotnet.net");
The Framework Class Library has an abstract class called System.Array. This is the base class for arrays in .NET and all arrays derive from this class. This means you can call methods of this class to get various information about the array, such as Length(), etc. Note that System.Array also implements IEnumerable which means you can have serial access to the array members using an enumerator, typically through the foreach construct in C# or VB.NET.
.NET has seven levels of access as shown in the table below. C++ is more expressive than X# because it allows you use all seven levels, whereas C# allows you to use only six. The first part of the C++ access specifier determines the access granted to types within the current assembly. The second part gives the access granted to types outside the current assembly:
| CLS Equivalent | C# | C++ | Meaning |
|---|---|---|---|
| public | public | public public or public |
Accessible by any code. |
| famorassem | protected internal | public protected | Accessible by types in the same assembly or by types derived from the containing type whether in the same assembly or not. |
| assem | internal | public private | Accessible by code in the same assembly only. |
| family | protected | protected protected
or protected |
Accessible by code in types derived from the containing type, whether in the same assembly or not. |
| famandassem | protected private | Accessible by code in types derived from the containing type only if they are in the same assembly. | |
| privatge | private | private private or private |
Accessible only by code in the containing type. |
| privatescope | (used on method static variables) | (used on method static variables) | Accessible only by code in the method where the static variable is declared. |
Interface programming is a very powerful technique. Interfaces describe behavior, they do not represent data storage nor do they represent implementation. Implementation is the responsibility of the class. Interfaces simply indicate a behavior that a type must implement. If an interface IStorage has a method called Read(), then one type (or class) implementing this interface may implement Read() to read some XML over HTTP, and another type (or class) implementing this interface may implement Read() to read from a file.
Note that a .NET type (i.e., class) may derive from many interfaces without violating the .NET requirement that a type can derive from only a single class. A great example for interfaces can be found in the .NET collection classes
The most important feature of .NET is metadata. Metadata is used by the runtime to determine the facilities that a type requires and to determine the context in which the object should run. Native code typically relies on compile-time checking, but with managed code, the runtime uses the metadata to perform its checks. And because metadata can describe everything in .NET, the runtime always knows what it is loading and running.
When you compile an assembly, the compiler adds into a part of the assembly called the Manifest a list of the assemblies that your code will use. The IL statements that make up your types describe exactly the members of the other types they call. When your code is executed, the .NET type system reads the type that your code requires, loads the requested assembly after the required version and security checks, and reads the metadata of the member that your code wants to call. If this description does not match the description of the member that your code want to call, the type will not be loaded. Your code will never call code that it does not intend to call.
The metadata can be extended so that you can accommodate types that are not in .NET. You extend metadata with classes called custom attributes. Custom attributes can be applied to any item in a source file. The values of the AttributeTargets enumeration indicate the items to which attributes can be applied. These include but are not limited to Assembly, Class, Constructor, Delegate, Enum, Event, Field, Interface, Method, Module, and others.
Using an attribute is straightforward. The general format is to give the name of the attribute in square brackets [] in front of the item to which the attribute applies. In some cases, using an attribute can be ambiguous. For example, does the attribute [info] apply to the method or the return value:
// C#
public class ExampleClass
{
[info] public int foo() { ... } //
[info] applies to return value or to method?
}
.NET languages provide a mechanism that uses prefixes to disambiguate attributes. C# and C++ differ in the exact for of some prefixes, for example while C# uses type for classes, structs, and enums, C++ explicitly says which type:
// C#
[type: MyClassAttr] class MyClass { ...
} // MyClassAttr is an attribute that is
applied to the class (type)
[type: MyStructAttr] struct MyStruct{ ... }
// MyStructAttr is an attribute that is applied to the
struct (type)
[return: info] public int foo() { ...
} //
Info is an attribute that is applied to the return value
// C++
[class: MyClassAttr] __gc class MyClass { ... }; //
MyClassAttr is an attribute that is applied to the class
[struct: MyStructAttr] __gc struct MyStruct{ ... }; //
MyStructAttr is an attribute that is applied to the struct
[returnvalue: info] public int foo() { ...
} // Info is an attribute
that is applied to the return value
Note that by convention, attribute classes have the suffix Attribute. However, C# and C++ allow you to omit this suffix, so in the examples above the attribute MyClassAttr was implemented by a class called MyClassAttrAttribute.
Attributes add metadata through an IL directive called .custom and for this reason they are called custom attributes. There are three types of custom attributes: custom attributes, distinguished custom attributes, and pseudo custom attributes.
pseudo custom attributes: Unlike other custom attributes, these attributes do not extend the metadata. Two examples are [Serializable] and [NonSerialized] used to indicate whether fields in a type are serialized. In this case, these two attributes merely turn or or off a flag to indicate whether the item to which the attribute was applied to can be serialized.
distinguished custom attributes: These attributes do not correspond to metadata defined by Microsoft. Distinguished custom attributes have data that is stored in the assembly alongside the items to which they apply. In IL distinguished custom attributes are indicated by the .custom keyword. It is a custom attribute because the metadata has been extended to take the attribute into account, but distinguished because the runtime knows about it.
An example of a distinguished custom attributes is [OneWay] which is typically used in .NET remoting. This attributes indicates to the runtime that the method does not have any return values or any out or ref parameters:
public class Listener
{
[OneWay] public void InformMe(string msg) {}
}
When this class is loaded, the .NET runtime can read the metadata attached to the Listener class by calling GetAttributes() static method on System.ComponentModel.TypeDiscriptor class. When GetAttributes() is called the attribute objects for the attributes that have applied to the class will be created and the appropriate constructor will be called for each attribute object. The attribute objects will be called only when the reflection API has been called. You do no incur the overhead of the attribute objects if the reflection API is not called.
The final type of attribute is simply called the custom attribute. Custom attributes also add metadata through the .custom keyword, but unlike distinguished custom attributes, these attributes mean nothing to the runtime.
The Framework contains many custom attributes and you can define yours as well. Defining your custom attribute is simple: Create a class that derives from System.Attributes and mark it with the [AttributeUsage] attribute to indicate the items to which your attribute can be applied.
Attributes can have mandatory parameters or optional named parameters. Mandatory parameter are implemented through constructor parameters on the attribute class. Named optional parameters are applied through fields or properties on the attribute class
/* C#: This attribute can only be
applied to classes. Compilers read the attribute usage of an attribute before
applying the attribute to an item and they will issue an error if the attribute
is being applied to an inappropriate item
*/
[AttributeUsage(AttributeTarget.Class, Inherited=false,
AllowMulitple=true)]
public class CommentAttribute : Attribute
{
// Data members
private string comment;
private bool isImportant = false;
// Constructors
/* Because parameters passed through constructors are unnamed
the order in which they appear is important.
In general unnamed parameters should be considered as
mandatory */
CommentAttribute( string str ) { comment = str;
}
// properties
/* Named parameters are implemented through public
fields or properties on the attribute class. The choice
of using a field or a property is determined by whether you
want the parameter to be read only (use a property
with get accessor only), or read/write (use a field). Also
note that properties are methods and you can do
more in a property such as checking certain invariants */
public string Comment { get{ return comment; } }
public bool isImportant { set{ isImportant = value; }
}
}
// C# - using the CommentAttribute
attribute. Note that the suffix 'Attribute' can be dropped
[Comment("FirstClass")]
public class FirstClass { ... }
[Comment("SecondClass", isImportant = true) ]
public class SecondClass { ... }
In the preceding example, the CommentAttribute may be defined in the same assembly as the items to which it is applied, and because it is public, it can be applied to items in other assemblies. If your attribute can be applied to assemblies or modules, you need to define in a separate assembly.
Attributes are read with the Reflection API. There are several ways to read the attributes on a type depending on whether you are reading the attribute on an instance of the type or through type metadata.
If you have an instance of the type, create an instance of System.Reflection.TypeDelegator class and call GetCustomAttributes() method to get an array of attributes:
// An instance of some class with
attributes you wish to read
MyAttributedClass c = new MyAttributedClass();
// Create an instance of TypeDelegator to help you read
attributes
TypeDelegator td = TypeDelegator( c.GetType() );
// Now read each attribute
foreach( object o in td.GetCustomAttributes(true) )
{
Console.WriteLine( o.ToString() );
}
Attributes extend metadata, but what use is that to you? First, understand that ehe metadata that you add is out of band and it is not read by the runtime. It is therefore, your responsibility to provide code that reads metadata using the reflection API. See Reading Attributes for an example.
You can use attributes in several ways:
/* This attribute class defines an
attribute that takes a mandatory value, the name of a file to which entries are
logged to */
[AttributeUsae(AttributeTarget.Class)]
public class CatalogAttribute : Attribute
{
public CatalogAttribute( string filename ) { ... }
...
}
/* Abstract class. All Catalog
classes must derive from this class */
public abstract class Catalogable
{
public Catalogable()
{
// This
constructor reads the Catalog attribute of the class and uses the file name
// to open and write to a log the
time this class was instantiated (for example)
...
}
...
}
/* Because MyCatalog derives from
Catalogable, when instances of MyCatalog class are created, the base class will
read the Catalog attribute and use the given file name to open and log entries
*/
[Catalog("object.txt")]
public class MyCatalog : Catalogable
{
...
}
A common problem in C and C++ comes from the facility in these languages to cast pointers to virtually anything you like using C style pointers.
// C#
public delegate void CompletedAction( string str );
// C++
public __delegate void CompletedAction(String* msg);
When you declare a delegate, the compiler will generate a sealed class with the same name as the delegate and derives it from MulticastDelegate. This class also contains four methods - a constructor, Invoke(), BeginInvoke() and EndInvoke(). Invoke(), BeginInvoke() and EndInvoke() are used to invoke the method or methods to which the delegate refers. Invoke() calls a method synchronously, while BeginInvoke() and EndInvoke() call a method asynchronously - the runtime will create a new thread and call the delegate's method(s) on this new thread meaning that the calling thread is not blocked and can do other work. When the calling thread knows that the method has completed, it can call EndInvoke() to complete the call and obtain the results.
/* C#: Class that implements the
delegate method. Note that the method called through the delegate can be an
instance of a static method */
public class ActionDone
{
public void OnCompleted(string str)
{ ... }
public static viod OnCompletedS( string str )
{ ... }
}
// C#
// Using implementation of a static method
CompletedAction ca = new CompletedAction( Actiondone.OnCompletedS );
// Using implementation of an instance method
ActionDone ad = new ActionDone();
CompletedAction ca2 = new CompletedAction( ad.OnCompleted );
// C++. The C++ compiler is not so
helpful. You must call the constructor with the object and method pointer
parameters
// Using implementation of a static method
CompletedAction* ca = new CompletedAction( 0, &ActionDone::OnCompletedS
);
// Using implementation of an instance method
ActionDone* ad = new ActionDone;
CompletedAction* ca2 = new CompleteAction( ad, &ActionDone::OnCompleted );
// C#
ca.Invoke( "called method"
); // OR
ca( "called method" );
//C++
ca->Invoke( S"called method" ); //
OR
ca( S"called method" );
// C#
ActionDone ad = new ActionDone();
CompleteAction ca = new CompleteAction(ad.OnCompleted);
ca += new CompleteAction(ActionDone.OnCompletedS);
// += calls the static Combine() from System.Delegate
class
The ca variable has now two delegates. When the delegate is invoked, both methods will be called and they will be called serially in the order in which they were added. Note that if one the methods throws an exception, the invocation will be stopped. It is therefore, important that you design the methods so that they do not throw exceptions.